在说正事之前,我要推荐一个福利:(你还在原价购买阿里云、腾讯云、华为云服务器吗?那太亏啦!来这里,新购、升级、续费都打折,能够为您省60%的钱呢!2核4G企业级云服务器低至69元/年,点击进去看看吧>>>),好了下面开始说正事:
本文以Kubernetes监控数据为例,介绍如何配置机器学习服务巡检时序数据并可视化展示异常巡检结果。
前提条件
背景信息
本案例中,用于存放时序数据的Logstore名称为etl-k8s-monitor,用于存储巡检结果的目标Logstore名称为ml-detector-res。源Logstore中采集到的时序数据日志样例如下图所示。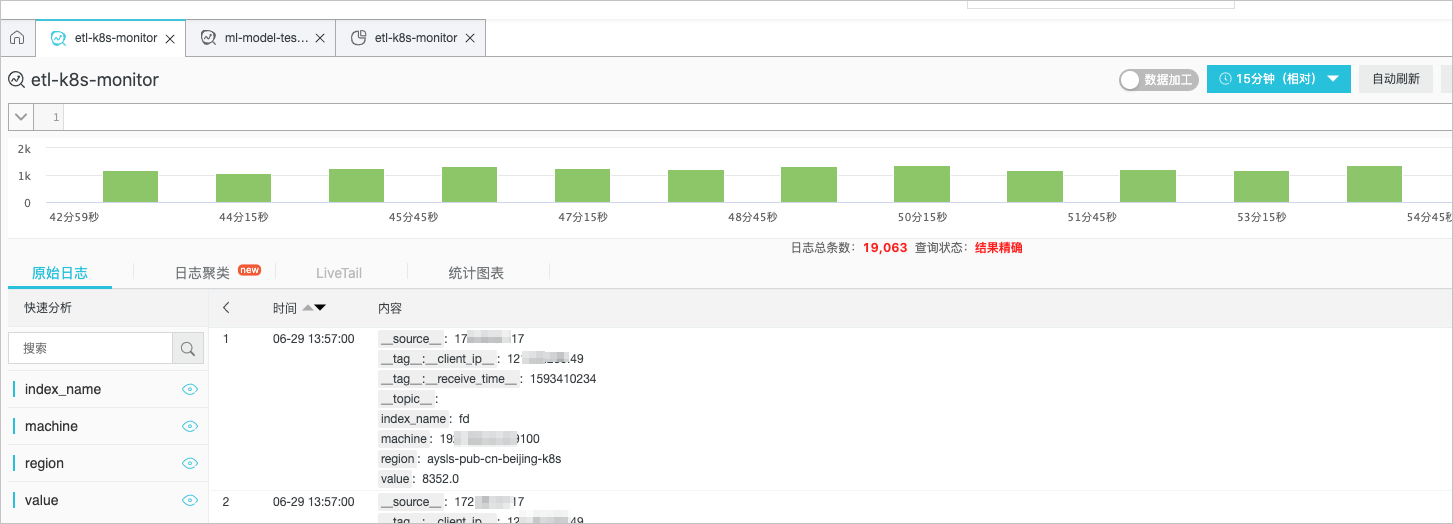
重要字段说明如下表所示。
| 字段 | 说明 |
|---|---|
| region | 表示一个集群。 |
| machine | 表示一台机器。 |
| index_name | 表示一个指标,例如负载,8个常用指标请参见表 1。 |
| value | 具体指标的数值。 |
步骤1:配置时序数据的索引
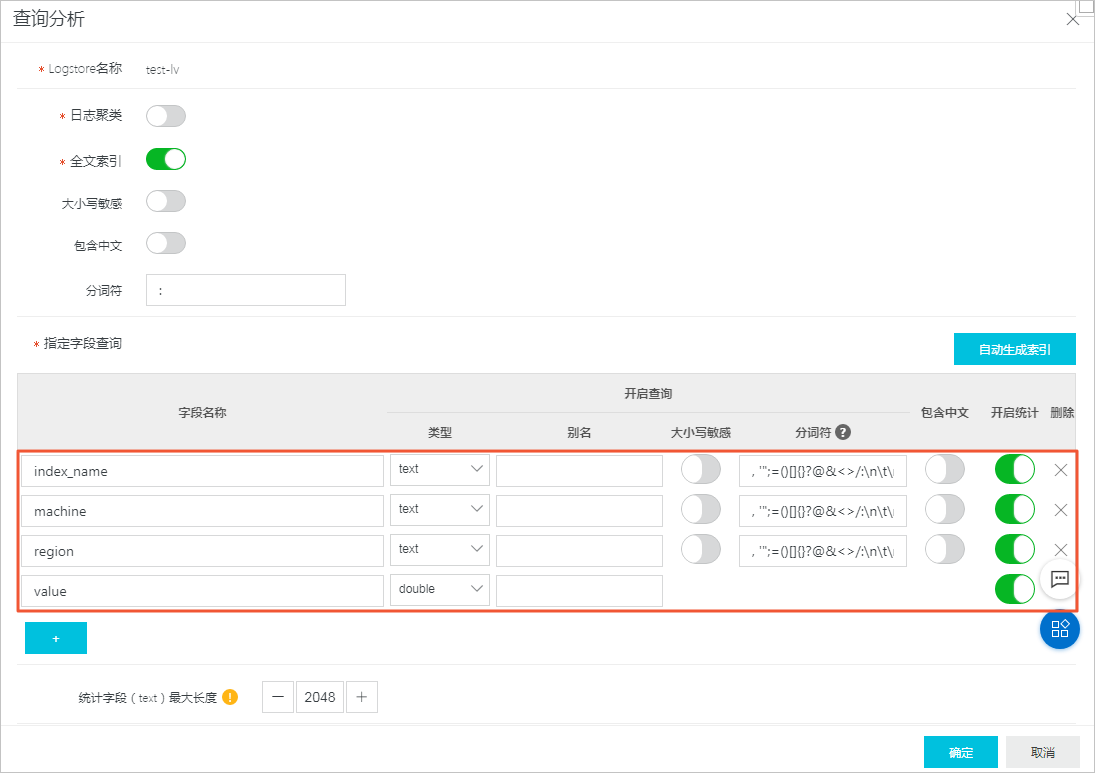
采集到时序数据后,您需要为相关字段配置字段索引。
- 在查询分析页面,配置字段索引。
步骤2:配置机器学习服务
您可以在保存数据加工时,配置机器学习服务。
- 在创建数据加工规则页面,配置相关参数,并单击确定。重要参数说明如下所示,其他参数配置请参见保存数据加工规则参数说明。
- 在AccessKey ID和AccessKey Secret参数中配置具有当前Logstore读权限且能创建消费组权限的AK信息,权限授权请参见RAM自定义授权场景。
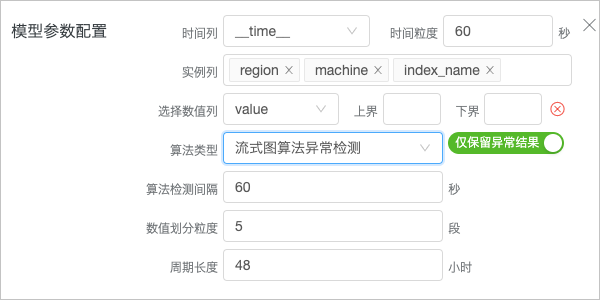
- 在模型参数配置参数中,配置机器学习服务。
此处以配置流式图算法异常检测为例,具体配置如下图所示。
 机器学习服务的相关参数说明如下表所示。
机器学习服务的相关参数说明如下表所示。参数 说明 时间列 用于标记时间的名称,所对应字段的值为Unix时间戳,只支持索引类型为long类型的字段。本案例选择__time__字段。 时间粒度 数据写入的粒度,即同一个实例中最小的数据间隔,单位:秒。本案例为60秒。 实例列 选择实例列,该字段标记了一条时序曲线的名称,只支持索引类型为text类型的字段。本案例选择region、machine和index_name,表示某地域中某台机器的某个指标。 选择数值列 某实例在某时刻的数值。本案例选择value。 上界 自定义阈值,如果您所选择的数值列的值大于该值,则直接判断为异常。 下界 自定义阈值,如果您所选择的数值列的值小于该值,则直接判断为异常。 算法类型 选择流式统计算法异常检测。如果您要使用流式统计算法异常检测,请参见流式统计算法异常检测。 仅保留异常结果 开启仅保留异常结果开关后,只保留异常结果到目标Logstore中。 算法检测间隔 指定发起算法检测异常的时间间隔,该值需小于等于时间粒度,单位:秒。本案例为60秒。 数值划分粒度 根据值域划分数据,单位:段,取值范围为[2,20],默认值为5。 分段越多,算法对异常越敏感,检测出的异常点越多。
周期时长 指定时序数据的周期长度,单位:小时,取值范围为[60, +∞),默认为时间粒度下,2880个时间点所对应的小时数。本案例为48小时。
完成配置后,日志服务启动机器学习服务,对时序数据进行巡检,将结果写入到目标Logstore。
步骤3:配置巡检结果数据的索引
- 查看巡检结果日志。
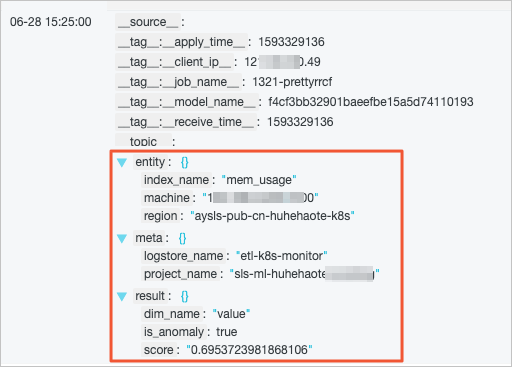
类型 字段 说明 entiy 无固定字段 表示一条时序曲线的实例列信息。 meta project_name 时序数据来源的Project。 logstore_name 时序数据来源的LogStore。 results dim_name 您所指定的数值列。 is_anomaly 流式图算法判断时序数据是否异常,Bool类型。 流式图算法默认以0.5为界线,如果score值大于0.5,则为异常,显示为true。
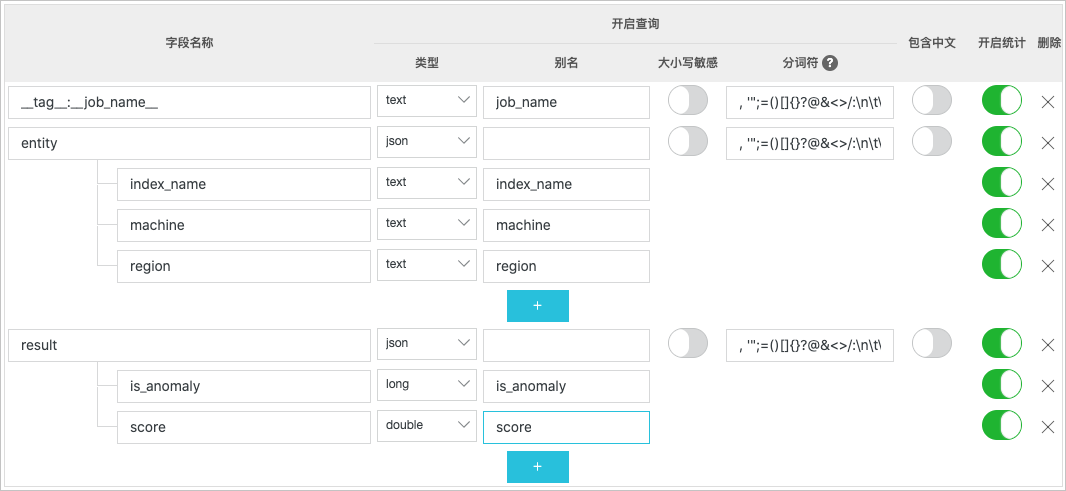
score 流式图算法输出的异常程度的量化分数,范围为[0,1],分数越大越异常。-1表示数据缺失。-2表示疑似异常(可能是因为流式图算法还未学习充分)。 - 配置索引。为__tag__:job_name__、entity、index_name、machine、region、result、in_anomaly和score字段配置索引,如下图所示,操作步骤详情请参见开启并配置索引。
步骤4:联合查询
您可以通过联合查询将异常结果整合到源Logstore中,帮助您快速了解算法模型的巡检结果。
- 在统计图表中,单击
 图标。
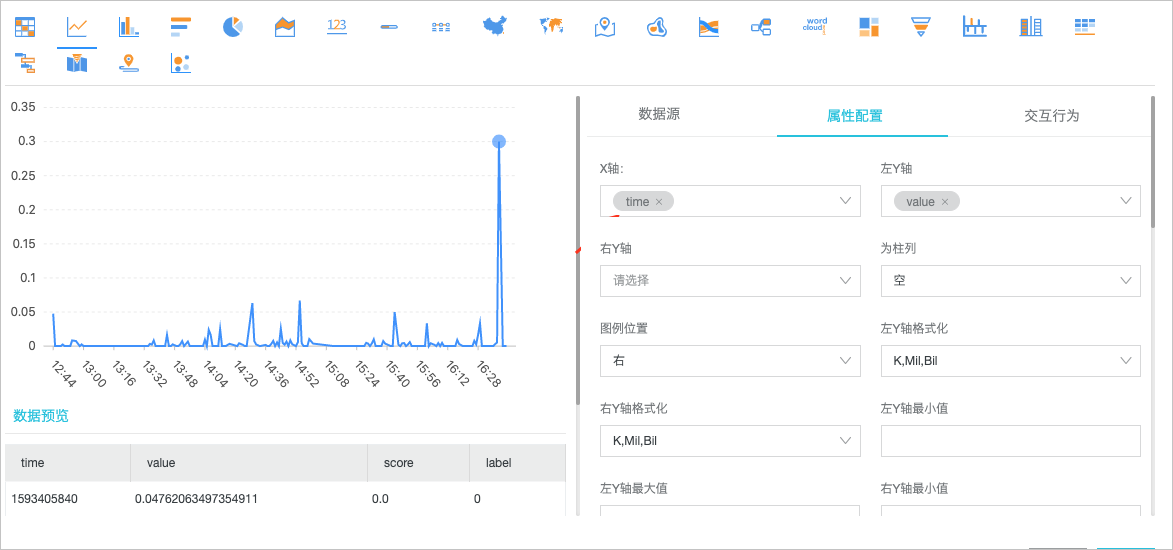
图标。通过折线图展示异常点时序曲线,其中X轴配置为time,左Y轴配置为value,散点列配置为value,散点数值列配置为label,其他参数配置请参见折线图。
步骤5:可视化展示
您还可以在分析数据时配置交互行为和过滤器,丰富仪表盘展示。
- 设置变量。
- 配置变量信息。
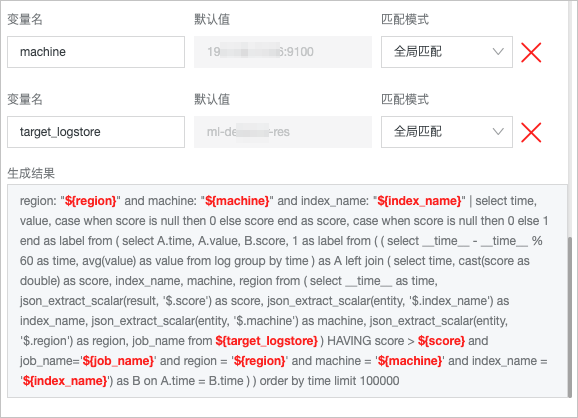
此处分别设置region、machine、target_logtore和index_name、score、job_name变量,如下图所示,参数详情请参见设置占位符变量。
- 配置变量信息。
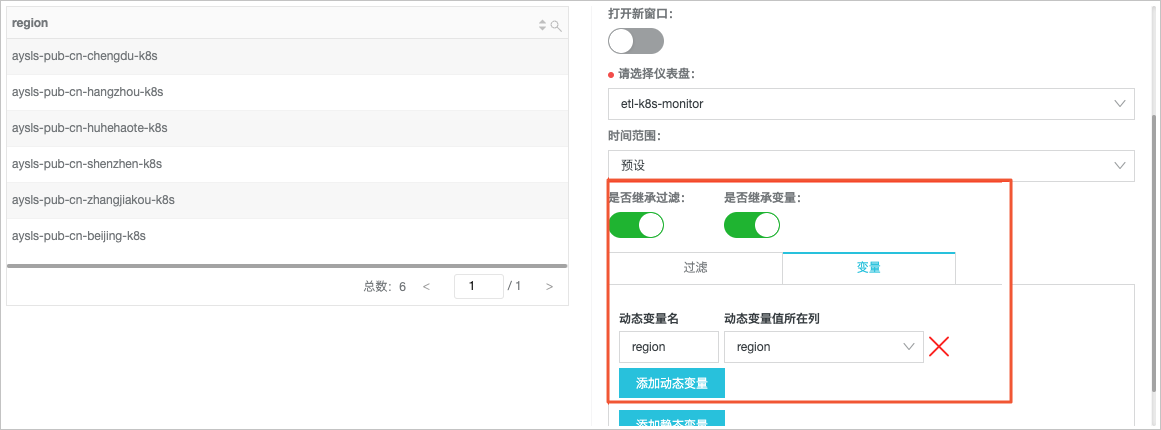
- 配置交互行为。此处以配置region变量的交互行为为例。
- 配置交互行为。相关参数配置如下图所示,详情请参见下钻分析。
- 配置交互行为。
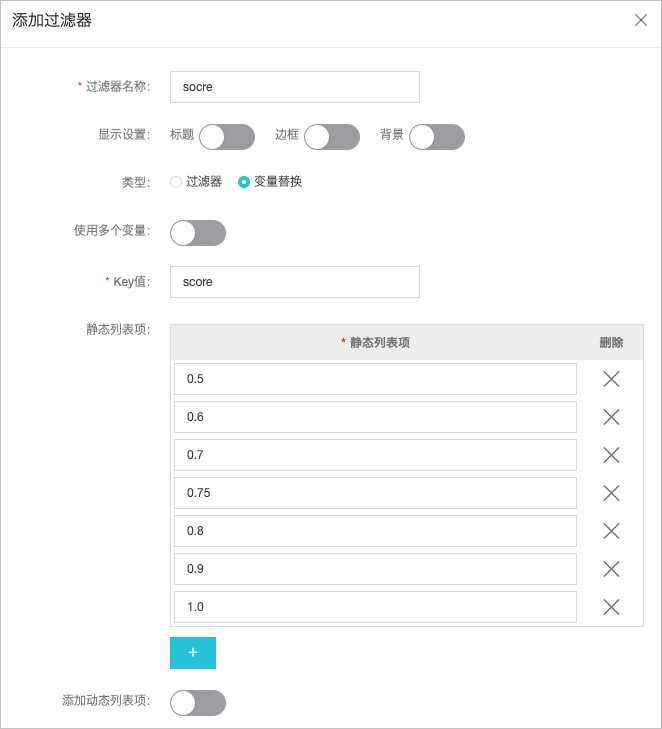
- 添加过滤器。此处以设置异常分数过滤器为例,您可以自定义设置异常分数,实现不同敏感程度的智能巡检。
- 在操作栏中,单击
 图标。
图标。 - 在添加过滤器页面,配置相关参数,并单击确定。相关参数配置如下图所示,详细操作步骤请参见添加过滤器。
- 在操作栏中,单击
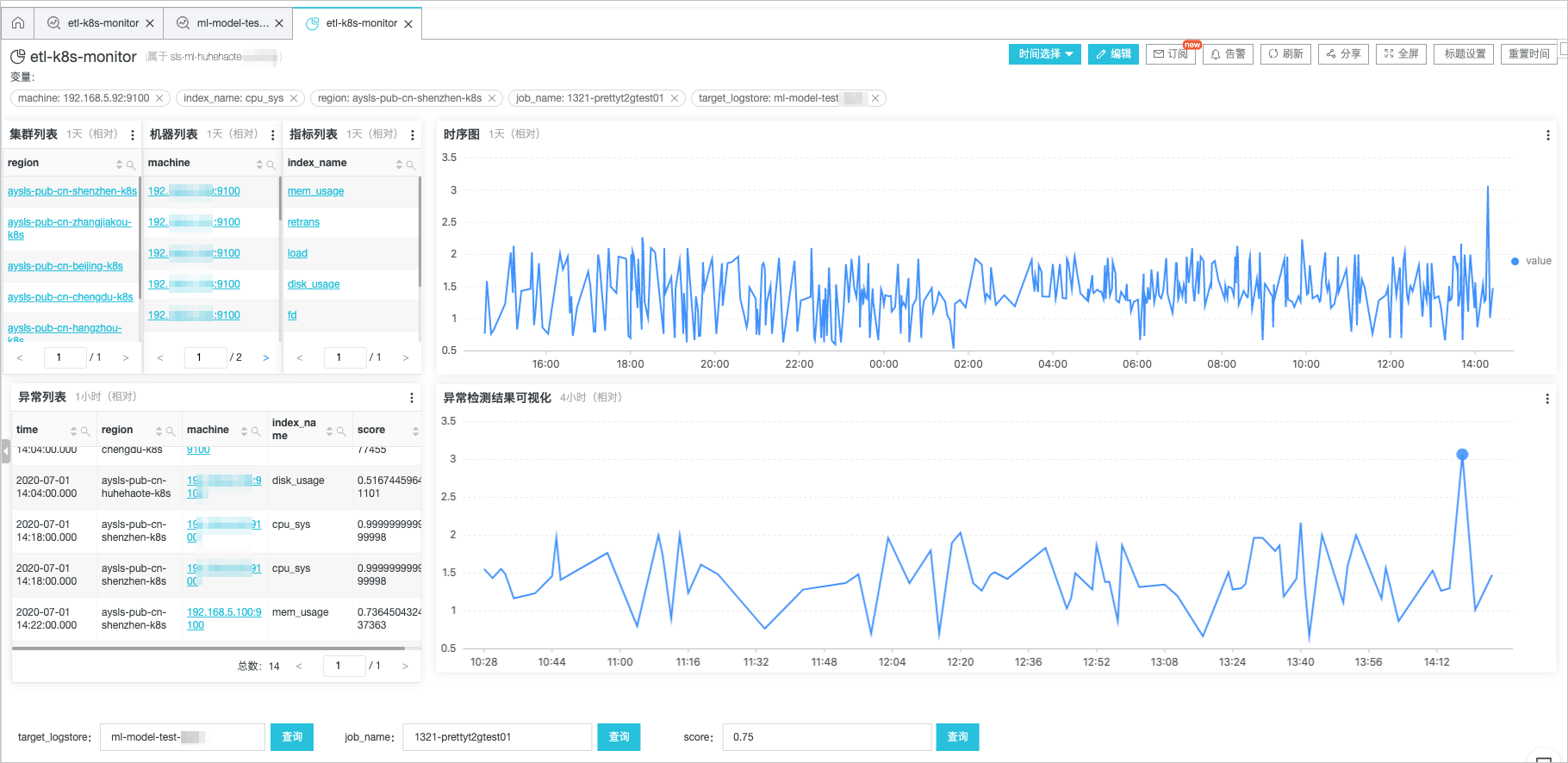
- 查看仪表盘。获取针对Kubernetes集群的智能巡检分析仪表盘。
步骤6:告警
您可以根据业务需求设置告警,获取智能化的告警通知,详情请参见设置告警。
