在说正事之前,我要推荐一个福利:(你还在原价购买阿里云、腾讯云、华为云服务器吗?那太亏啦!来这里,新购、升级、续费都打折,能够为您省60%的钱呢!2核4G企业级云服务器低至69元/年,点击进去看看吧>>>),好了下面开始说正事:
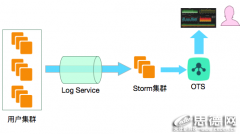
使用云服务最大好处是按量付费,无需预留资源,因此各云产品都有计量计费需求。这里我们介绍一种基于日志服务计量计费方案,该方案每天处理千亿级计量日志,被众多云产品使用。
计量日志生成计费结果过程
计量日志记录了用户涉及计费的项目,后台计费模块根据计费项和规则进行运算,产生最后账单。例如如下原始访问日志记录了项目(Project)使用情况:
microtime:1457517269818107 Method:PostLogStoreLogs Status:200 Source:10.145.6.81 ClientIP:112.124.143.241 Latency:1968 InFlow:1409 NetFlow:474 OutFlow:0 UserId:44 AliUid:1264425845****** ProjectName:app-myapplication ProjectId:573 LogStore:perf UserAgent:ali-sls-logtail APIVersion:0.5.0 RequestId:56DFF2D58B3D939D691323C7
计量计费程序读取原始日志,根据规则生成用户在各维度使用数据(包括流量、使用次数、出流量等):

典型计量日志计费场景
- 电力公司:每10秒会收到一条日志,记录该10秒内每个用户ID下该周期内功耗、峰值、均值等,每天、每小时和每月给用户提供账单。
- 运营商:每隔10秒从基站收到时间段内某个手机号码的动作(上网、电话、短信、VoIP),使用量(流量),时长等信息,后台计费服务统计出该区间内消耗资费。
- 天气预测API服务:根据用户调用接口类型、城市、查询类型、结果大小等对用户请求进行收费。
要求与挑战
既要算对,又要算准是一件要求很高的事情,系统要求如下:
- 准确可靠:既不可多算,也不能少算。
- 灵活:支持补数据等场景,例如一部分数据没有推送过来,当需要修正时可以重新计算。
- 实时性强:能够做到秒级计费,对于欠费场景快速切断。
其他需求(Plus):
- 账单修正功能:在实时计费失败时,我们可以通过理想计费进行对账。
- 查询明细:支持用户查看自己消费明细。
现实中还有两类挑战:
- 不断增长的数据量:随着用户以及调用上升,数据规模会越来越大,如何保持架构的弹性伸缩。
- 容错处理:计费程序可能有Bug,如何确保计量数据与计费程序独立。
本文档主要介绍一种阿里云基于日志服务开发计量计费方案,该方案已在线上稳定运行多年,从未出现过一例算错、延迟等情况,供单价参考。
系统架构
以阿里云日志服务的LogHub功能为例:
- 使用LogHub进行计量日志实时采集与计量程序对接:LogHub 支持的30+种API和接入手段,接入计量日志非常容易。
- 计量程序每隔固定时间消费LogHub中步长数据,在内存中计算结果生成计费数据。
- (附加)对明细数据查询需求,可以将计量日志配置索引查询。
- (附加)将计量日志推送至OSS、MaxCompute进行离线存储,进行T+1等对账与统计。
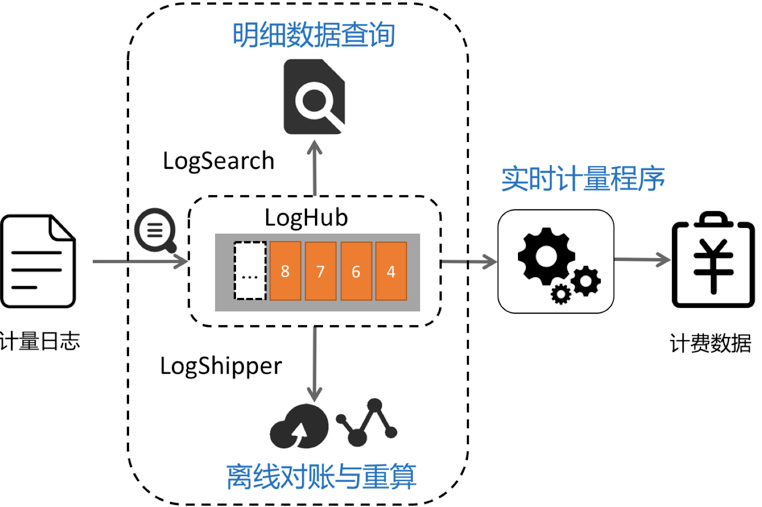
实时计量程序内部结构:
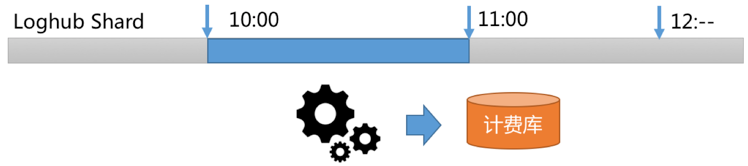
- 根据LogHub读取接口GetCursor功能,选定某个时间段日志(例如10:00-11:00)Cursor。
- 通过PullLogs接口消费该时间段内数据。
- 在内存中进行数据统计与计算,拿到结果,生成计费数据。
我们可以以此类推,把选择时间计算逻辑修改为1分钟,10秒钟等。
性能分析:
- 假设有10亿条/天计量日志,每条长度为200字节,数据量为200GB。
- LogHub 默认SDK或Agent都带压缩功能,实际存储数据量为40GB(一般至少有5倍压缩率),一个小时数据量为40/24 = 1.6GB。
- LogHub读取接口一次最大支持读1000个包(每个包最大为5MB),在千兆网条件下2秒内即可读完。
- 加上内存中数据累计与计算时间,对1小时计量日志进行汇总,不超过5秒。
数据量大应如何解决
在一些计费场景下(例如运营商、IoT等)计量日志量会很大(例如十万亿,数据量为2PB/Day),折算压缩数据后一小时有16 TB,以万兆网络读取需要1600秒,已不能满足快速出账单需求。
1. 控制产生的计费数据量
我们对于产生计量日志程序进行改造(例如Nginx),先在内存中做了聚合,每隔1分钟Dump一次该时间段聚合的汇总计量日志结果。这样数据量就和总体的用户数相关了:假设Nginx该时间段内有1000个用户,一个小时数据点也才1000 * 200 * 60 = 12 GB(压缩后为 240 MB)。
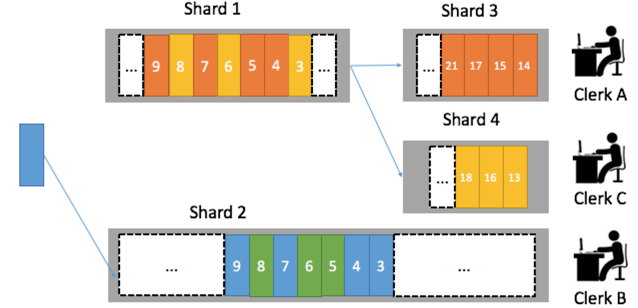
2. 将计量日志处理并行化
LogHub下每个日志库可以分配不同Shard(分区),我们可以分配3个分区,3个计量消费程序。为了保证一个用户计量数据总是由一个消费程序处理,我们可以根据用户ID Hash到固定Shard中。例如杭州市西湖区用户写在1号Shard,杭州上城区用户数据写在2号Shard,这样后台计量程序就可水平扩展。
其他问题
- 补数据怎么办?
LogHub 下每个Logstore可以设置生命周期(1-365天),如果计费程序需要重新消费数据,在生命周期内可以任意根据时间段进行计算。
- 计量日志散落在很多服务器(前端机)怎么办
- 使用Logtail Agent实时采集
- 使用机器标示定义一套动态机器组弹性伸缩
- 查询明细需求如何满足
对LogHub中数据可以创建索引,支持实时查询与统计分析,例如我们想调查有一些特别大的计量日志:
Inflow>300000 and Method=Post* and Status in [200 300]在对Loghub中数据打开索引后,即可实时查询与分析。

也可以在查询后加上统计分析:
Inflow>300000 and Method=Post* and Status in [200 300] | select max(Inflow) as s, ProjectName group by ProjectName order by s desc

- 存储日志并进行T+1对账
日志服务提供LogHub中数据投递功能,支持自定义分区、自定义存储格式等将日志存储在OSS/MaxCompute上,利用E-MapReduce、MaxCompute、HybridDB、Hadoop、Hive、Presto、Spark等进行计算。